Building a Financial Chatbot Prototype (in 4 Weeks)

When one of our partners challenged us to explore the integration of AI in a real-world financial context, the goal was clear: to build, in record time (4 weeks!), a chatbot capable of providing useful answers about credit consolidation.
At CRON STUDIO, we approached the challenge with our usual venture building mindset, starting from a Minimum Viable Product (MVP) philosophy. Rather than aiming for complexity or completeness from day one, we focused on shipping a solution that was simple, useful, and measurable. This allowed us to validate core assumptions early, deliver tangible value, and leave room for smarter iterations in the future.
What does this mean in practice? With this prototype, a user can have a natural conversation, with precise calculations, where they:
Ask ”Can I combine my mortgage with my car loan?” and get an instant estimate of the new monthly payment and potential savings.
Say “How much would I pay if I reduce the term from 30 to 20 years” and see a clear recalculation on the spot, without the possibility of hallucinations.
Request ”How can I move forward with this offer?” and be redirected to a specific credit advisor who can help close the deal.
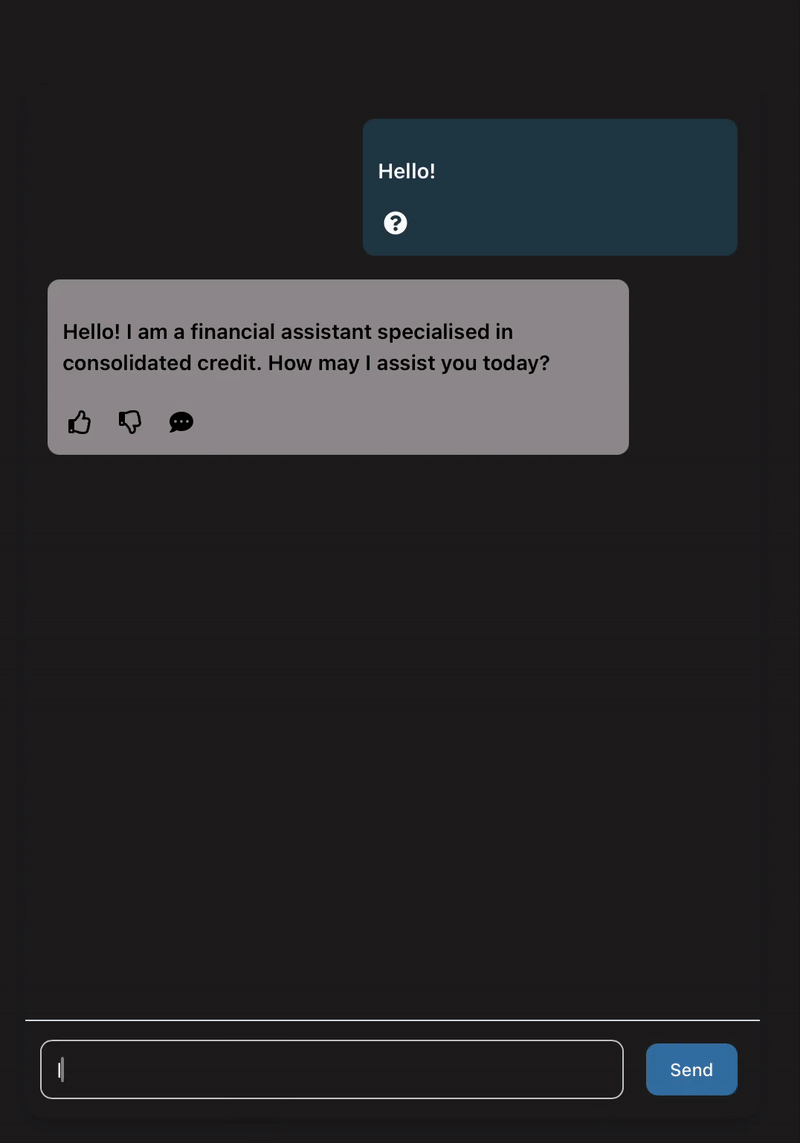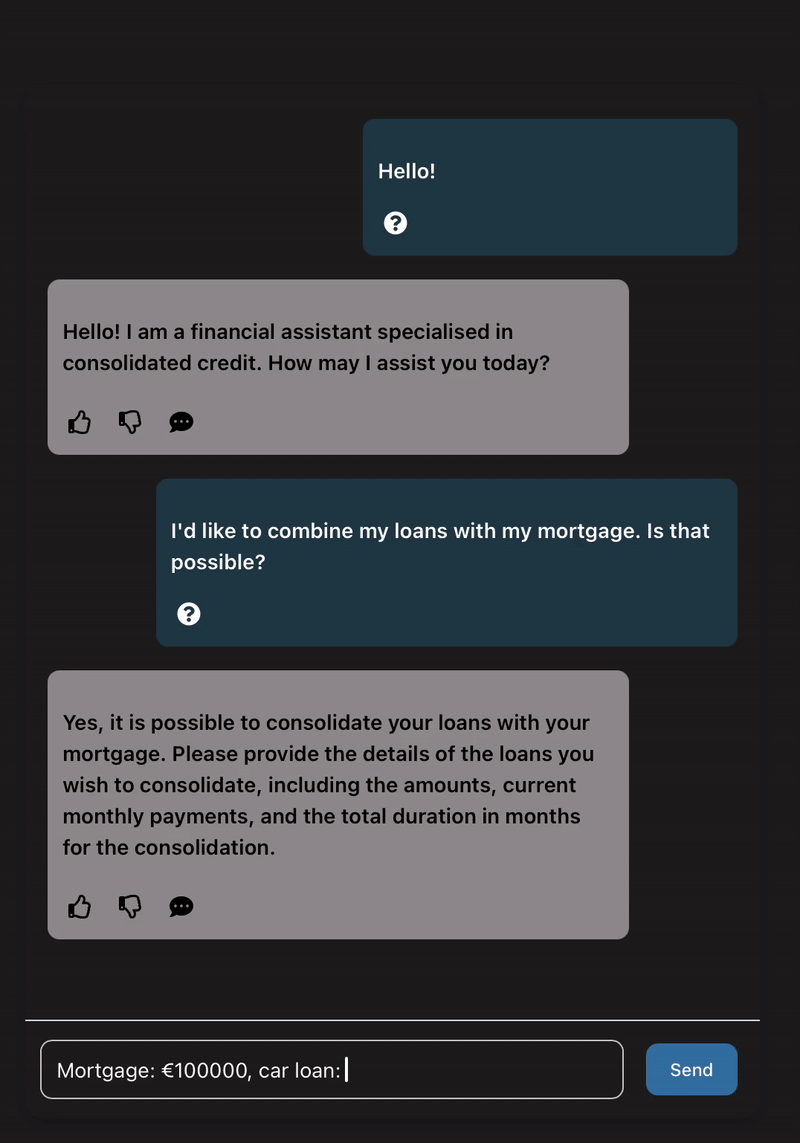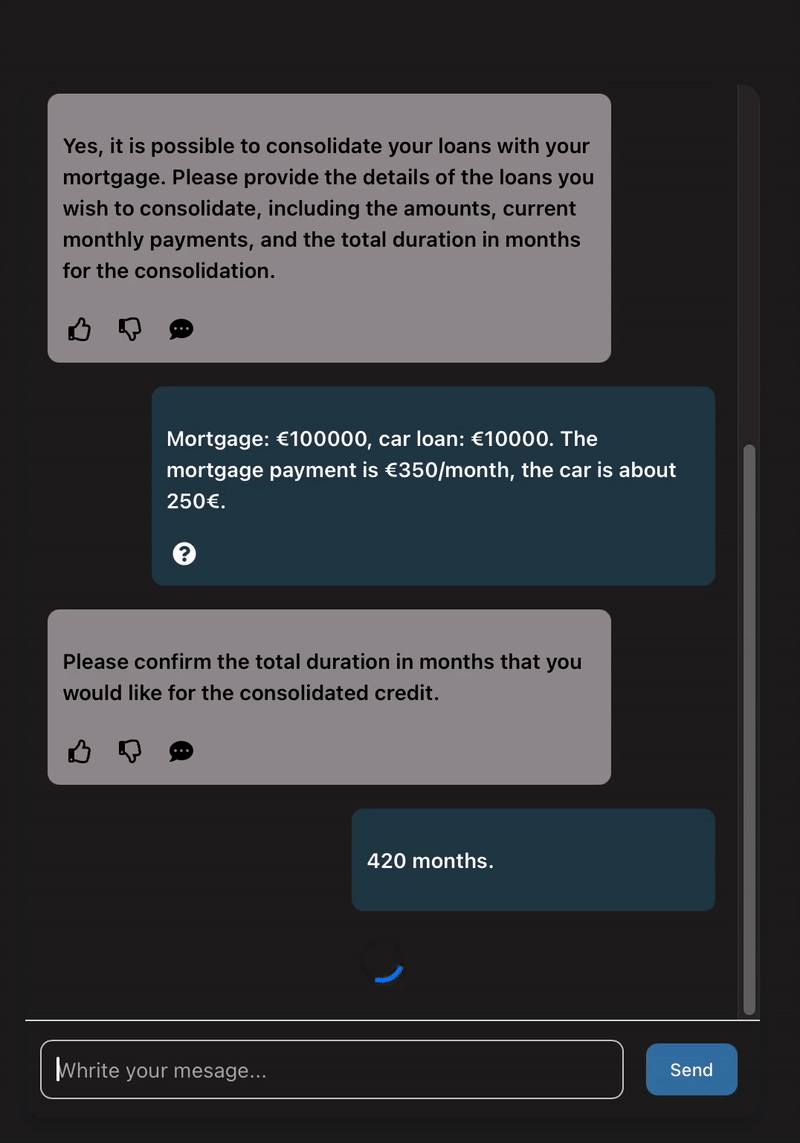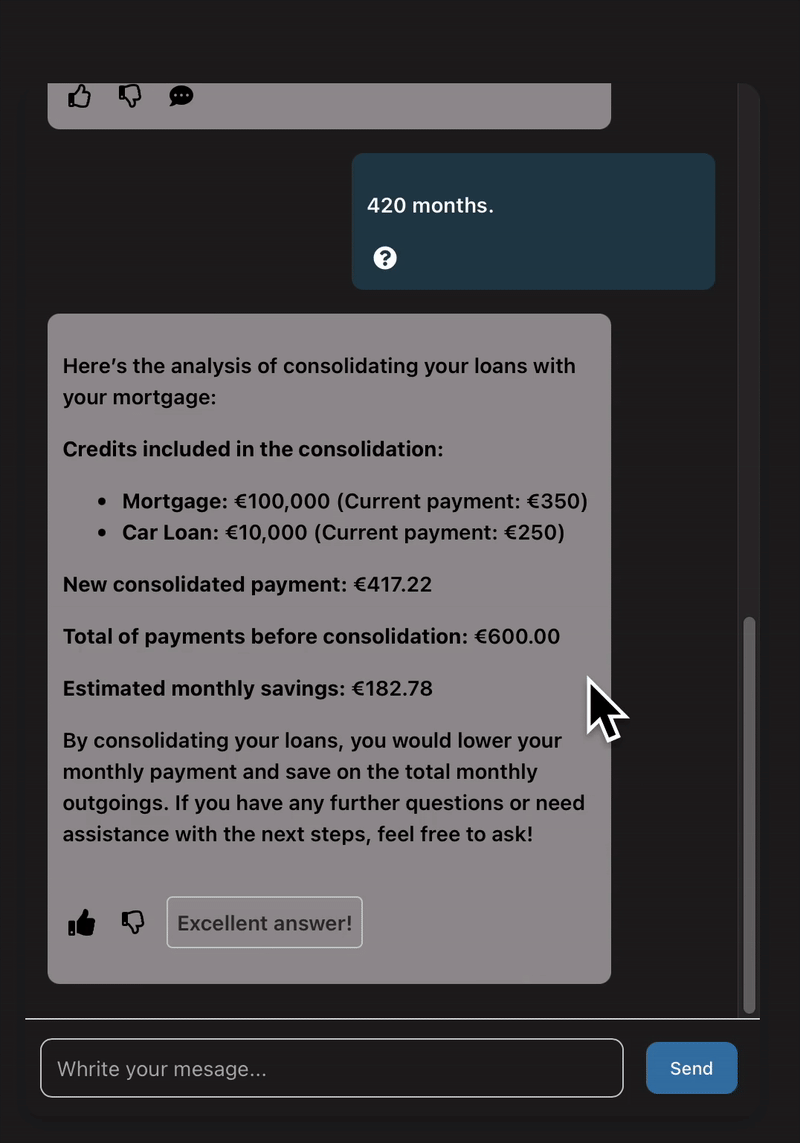
In this blog post, we want to share how we built this prototype and some of our key takeaways, so you can get a feel for how we work, or maybe have a shot at building your own prototypes. 🙂
Building a Functional Prototype in One Month
The architecture was designed for clarity and speed. We used Django to structure and expose the business logic through a clean API, keeping server-side responsibilities predictable and easy to evolve. On the frontend, React provided a lightweight interface focused purely on the user experience.
The chatbot logic was designed to be as simple and predictable as possible: the LLM interpreted user intent, while our backend returned results based on real financial calculations and logged each message-response pair for traceability and improvement. This made the system easy to test and iterate, while laying the groundwork for smarter, more stateful behavior in the future.
Designing a Conversational Experience That Feels Natural
When designing the chatbot experience, we had to find a balance between control and flexibility. While some chatbots are fully scripted and others completely open-ended, we aimed for something in between: a system where user input could trigger precise calculations, but the assistant still sounded natural and helpful.
To this end, we decided to use OpenAI’s function calling. It allowed us to inject precision into the conversation without sacrificing a natural tone. For example, when a user asks, “Can I consolidate all my loans?”, the LLM understands the intent and, once it has the necessary information, triggers a backend simulation tailored to the user’s case without breaking the conversational flow.
Initially, we explored the idea of routing common questions through a lightweight classification layer matching frequent inputs with predefined responses. We even considered embedding-based similarity searches. But in the interest of speed and clarity, we opted to let the LLM handle most requests, using OpenAI’s function calling to cover our core use cases with precision.
Even so, we laid the foundation for something more powerful: every user message is logged and can be tagged with its intent, creating a dataset for smarter routing in the future. This means the chatbot could one day respond even faster and cheaper without compromising on clarity or experience.
Saying No Is Part of Building Well
When building something in just four weeks, choosing what not to do is just as important as deciding what to include. We knew early on that the temptation to over-engineer, add real time features, build advanced user models, or fine-tune an LLM would only slow us down.
We considered several options that, while interesting, didn’t make sense at this stage. For example:
WebSockets were unnecessary for a request-response interaction model.
Embedding-based search added complexity without clear short-term benefit.
LLM fine-tuning wasn’t viable without a strong dataset of curated examples.
What we said “no” to was just as deliberate as what we built. It allowed us to focus on delivering something real, and left the door open to smarter upgrades in the future.
Internal Testing & Feedback Loops
Rather than waiting for a finished version to get feedback, we gave early testers the tools to shape the chatbot in real time. By allowing each message to be rated and commented on, we opened a direct line between users and the product’s core behavior.
This wasn’t just useful, it was transformative. With this data, we could generate feedback reports, adjust the system prompt, add or remove behaviors, and catch misalignments early. We discovered that some things the chatbot could do weren’t things it should do and we wouldn’t have known that without this loop.
What began as a simple evaluation mechanism ended up being one of the most valuable parts of the build. It kept us grounded in real use cases and gave us confidence in the direction of the final product.
Real Constraints, Real Challenges
Working with financial data meant being precise both technically and in tone. We had to represent loan conditions, simulate consolidation scenarios, and answer nuanced user questions, all without misleading or oversimplifying. That required careful alignment between frontend phrasing, backend logic, and model prompts.
We also had to deal with technical uncertainty. Even with tools like OpenAI’s function calling, responses can vary depending on how the model interprets the context. Ensuring repeatability across conversations meant iterating on prompt design, request formatting, and edge-case handling.
Choosing the right model was part of the challenge. Since this was an MVP, we prioritized a balance between performance, cost, and future-proofing. We selected a variant of GPT-4o mini, OpenAI’s cost-efficient small model, which provided strong results in function calling, reasoning, and multilingual support all at a fraction of the cost of larger models. The lesson? Model selection is not just about capability: it’s about timing, cost-effectiveness, and alignment with the product’s maturity. GPT-4o mini gave us what we needed: reliable intelligence, fast responses, and the flexibility to upgrade later.
Key Takeaways for Future Projects
Value doesn’t come from adding complexity, but from solving the right problems simply. This project reminded us that the best prototypes don’t just demo features – they prove usefulness.
Start with constraints, not features: instead of asking “what can we build?”, we asked “what must this solve, and under which limits?”. This flipped the mindset from open-ended ideation to focused problem-solving. The boundaries we drew early on saved time, reduced ambiguity, and helped align everyone around what mattered most.
Stabilize the core experience before expanding: it’s tempting to add features, polish edge cases, or integrate new APIs. But we prioritized getting one thing right: a smooth, helpful, trustworthy chat experience. Only after that foundation was solid would other additions make sense and that discipline paid off in clarity and coherence.
Say no to distractions: we deliberately avoided premature complexity: no fine-tuned LLMs, no embedded search engines, no real-time infrastructure. These weren’t rejected forever, just deferred until the need and timing were right. This kept the system lean and maintainable, while still leaving room to evolve.
Treat AI as infrastructure, not magic: we realized early on that function calling was essential for our use cases. We couldn’t rely on the model to guess everything, so we shaped the experience with structure, guidance, and fallback logic.
Build feedback into the system: user experience feedback wasn’t just “nice to have” – it was part of the product. Letting testers rate responses and leave comments created a loop we used to actively improve behavior, messaging, and even prompt design.
Think modular from day one: even in a prototype, we aimed for components that could be reused, replaced, or scaled. That applied to backend logic. We didn’t over-abstract but we did leave doors open for smarter versions later. This is easier said than done – but, then again, that’s why we consider ourselves great engineers.
Outcome and Next Steps
In only four weeks, we delivered a fully functional prototype that met the core requirements: users could ask natural questions about credit consolidation and receive personalized, mathematically accurate, data-backed answers all within a clean and usable interface.
We considered the project a success, not because it was flawless, but because it worked where it mattered most. Users received relevant answers, interactions felt natural, and the underlying system proved stable and adaptable. Early feedback suggested the assistant was already helpful and intuitive, not perfect, but promising.
More importantly, the foundation we built was solid: a modular system, a growing dataset of real interactions, and a clear sense of where to go next. For our partner, this isn’t just a prototype, it's a credible springboard for future iterations, deeper integrations, and smarter automation.
We proved that an LLM-powered assistant can offer meaningful guidance on a topic as sensitive and complex as personal finance. And we did it without overpromising, overengineering, or losing sight of what users actually need: clear, honest, and helpful answers.
Next steps? Version 2.0 – coming soon.
Article written by Tiago Caniceiro
Want to learn more about how we create AI solutions that make a difference? Let’s talk!